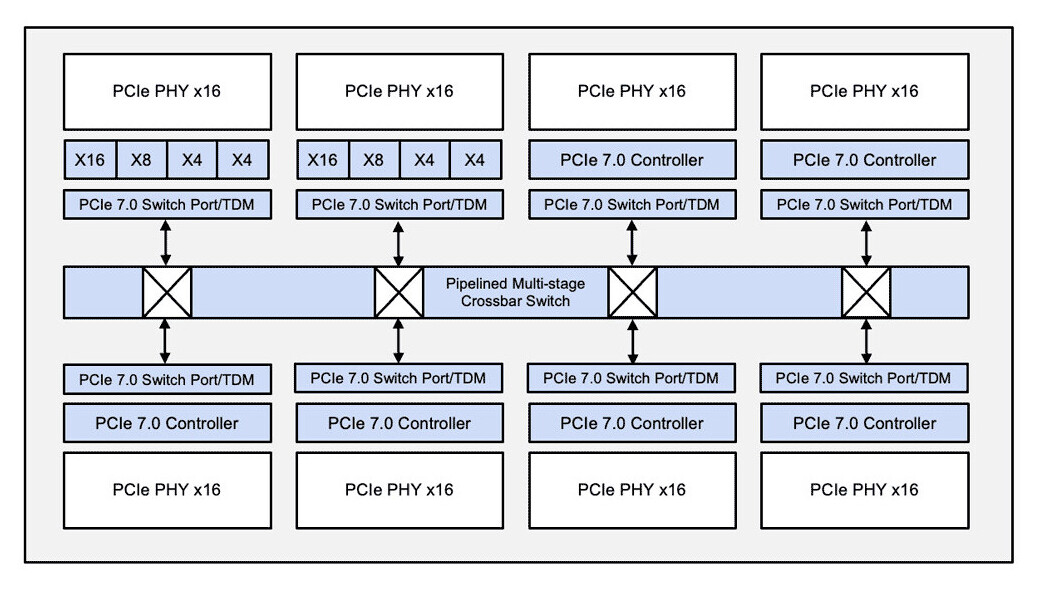
workloads are no longer just about raw computational power—they demand precision in how data moves through systems. Rambus has addressed this with its PCIe 7.0 switch IP, which leverages time division multiplexing (TDM) to streamline traffic across AI and HPC architectures.
Traditional PCIe designs often scale by adding more lanes or endpoints, but this approach can lead to inefficiencies. Rambus’s solution flips that model, using TDM to dynamically allocate bandwidth where it matters most—whether for high-throughput AI training or low-latency inference tasks. This isn’t just about moving more data; it’s about moving it smarter.
Key Advancements
- PCIe 7.0 Support: Fully compliant with the latest specification, ensuring seamless integration with next-gen accelerators and SoCs.
- TDM for Traffic Optimization: Reduces contention by intelligently scheduling data flows, improving link utilization without brute-force scaling.
- Scalability Without Complexity: Designed to grow with AI/HPC demands while maintaining system simplicity and performance.
The switch IP joins Rambus’s broader portfolio of PCIe solutions, including controllers and retimers. Together, these components aim to accelerate development cycles while meeting the rigorous needs of modern AI infrastructure—balancing speed, efficiency, and reliability.
Why TDM Matters
Conventional PCIe scaling hits a wall: more lanes often mean more overhead without proportional gains. Rambus’s TDM approach breaks that cycle by ensuring bandwidth is allocated precisely where it’s needed, delivering deterministic performance. For AI and HPC systems, this could mean fewer bottlenecks and more predictable scalability.
As AI and HPC push boundaries, innovations like this will shape the future of interconnects—making data movement as intelligent as the workloads themselves.