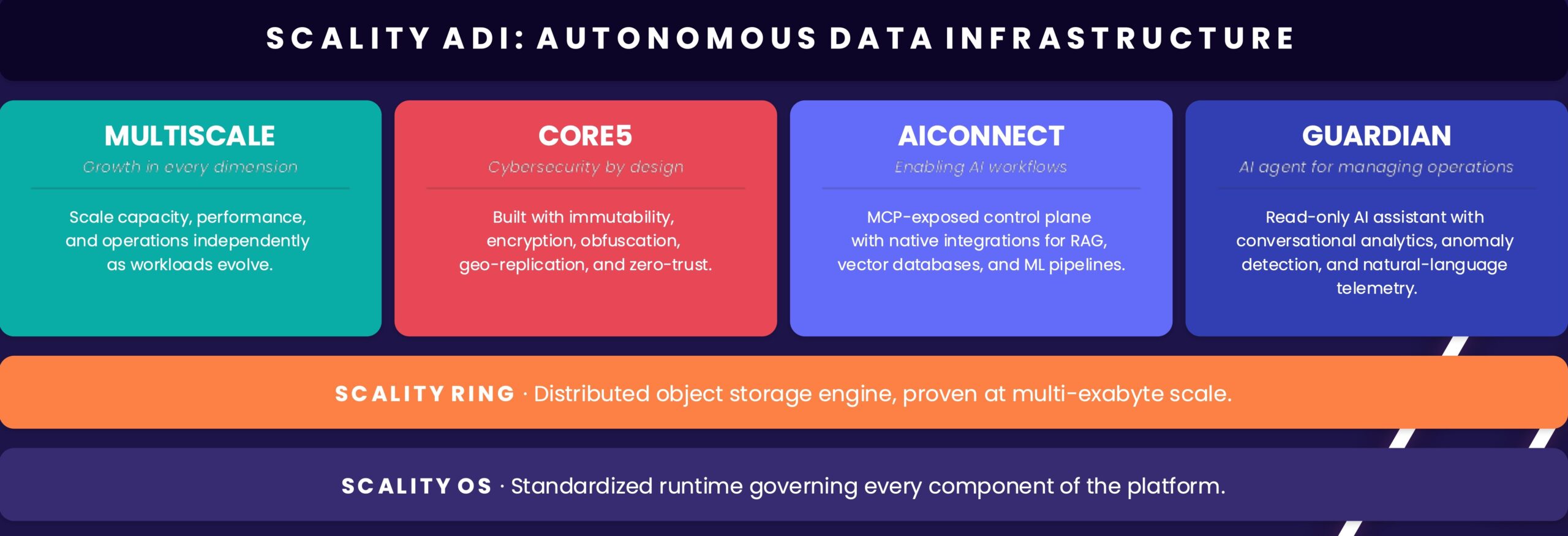
inference systems are hitting a familiar wall: memory capacity can’t keep up with demand. That’s where MinIO’s new MemKV engine steps in, designed specifically for petabyte-scale workloads that push traditional storage engines to their limits.
The engine, built from the ground up for AI, rethinks how data is cached and retrieved during inference tasks. It avoids the bottlenecks seen in object stores by treating memory as both a cache and a durable layer, ensuring low-latency access without sacrificing persistence. This isn’t just about speed—it’s about maintaining performance when datasets grow beyond what RAM alone can handle.
Key to its approach is a separation of concerns: transient data lives in fast memory, while long-term storage remains on disk or object storage like S3-compatible backends. This dual-layer design allows developers to scale inference workloads without the usual trade-offs between speed and durability. Benchmarks suggest significant improvements over existing solutions, particularly in scenarios where models are larger than available RAM.
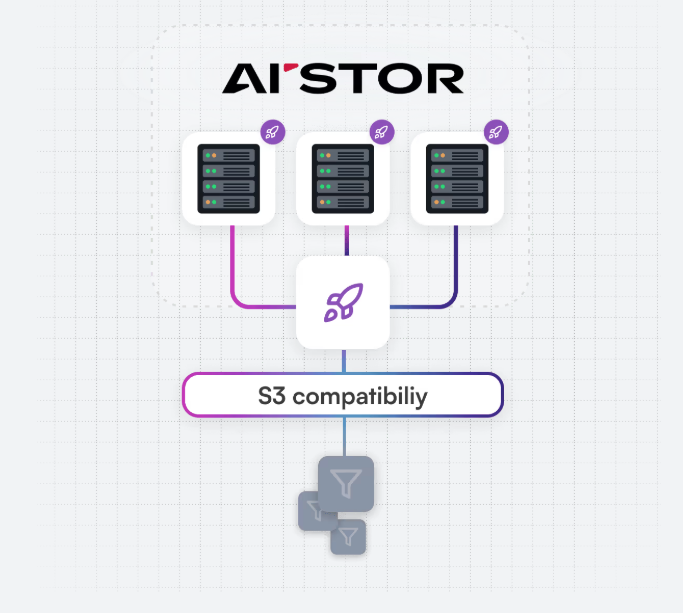
Why this matters: For developers building AI systems that need to handle massive datasets—think real-time analytics or large-language-model serving—MemKV offers a way to decouple compute from storage constraints. The engine’s API is compatible with existing MinIO deployments, meaning teams can integrate it without overhauling their infrastructure.
That’s the upside—here’s the catch. MemKV isn’t a replacement for traditional object storage; it’s an addition. Teams will still need to manage their primary data layers, but they’ll gain a specialized tool for the high-speed, high-volume inference tasks that are becoming more common as models grow.
For now, the focus is on stability and real-world testing, with plans to expand its capabilities in future releases. The question isn’t whether this will work—it’s how quickly developers will adopt it when faced with the next wave of AI scaling challenges.