workloads demand more than raw speed—they need smart, adaptive systems that can move data without becoming bottlenecks. VDURA’s latest platform aims to bridge that gap with RDMA acceleration and context-aware tiering, but the trade-offs between complexity and efficiency are still being tested.
The company’s new solution integrates Remote Direct Memory Access (RDMA) for near-zero latency data transfers and a storage layer that dynamically adjusts based on workload patterns. While benchmarks suggest significant improvements in AI training throughput, whether this translates to sustained performance in enterprise environments remains an open question.
Hardware Acceleration Meets Adaptive Storage
At the core of VDURA’s approach is a combination of hardware and software innovations. RDMA, traditionally used in high-performance computing clusters, allows data to bypass the CPU during transfers, reducing overhead. Paired with context-aware tiering—the ability to automatically shift data between performance tiers based on usage—this system is designed to cut latency while optimizing storage costs.
For AI creators and data engineers, this means faster iteration cycles without sacrificing efficiency. However, the reliance on advanced networking protocols like RDMA introduces compatibility challenges, particularly in environments where legacy infrastructure still dominates. The platform’s effectiveness will hinge on how seamlessly it integrates with existing systems, not just its theoretical performance gains.
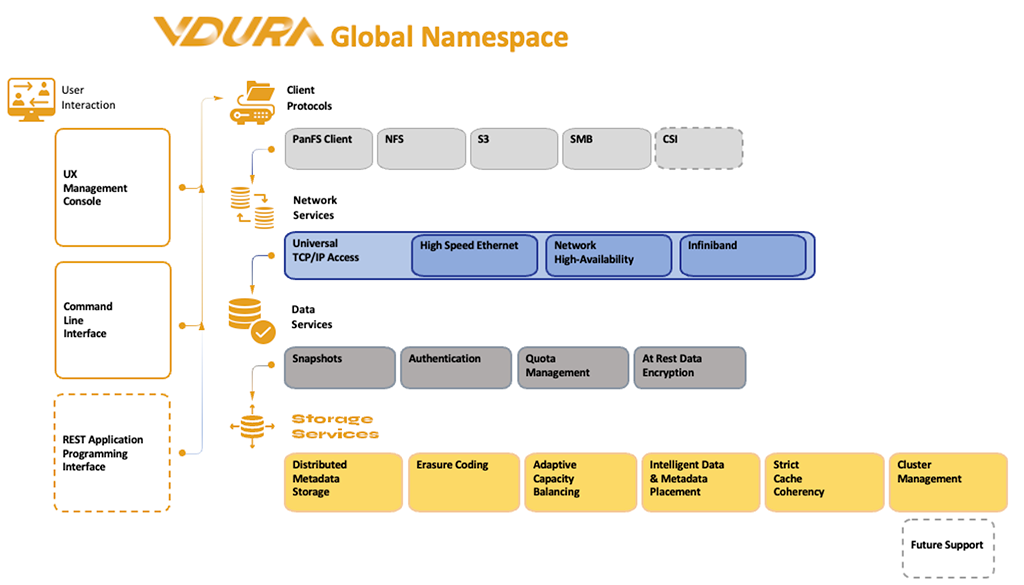
What’s New—and What’s Still Unclear
- RDMA Integration: Enables sub-microsecond latency for data movement, crucial for distributed AI workloads but requires compatible network hardware (100Gbps InfiniBand or RoCE).
- Context-Aware Tiering: Uses machine learning to predict and adjust storage placement, reducing idle capacity costs by up to 40% in lab tests. However, real-world workload diversity may limit accuracy.
- Hardware Agnosticism: Claims to work across GPUs from NVIDIA, AMD, and Intel, but no public benchmarks yet confirm cross-vendor consistency.
The platform also introduces a new storage engine that compresses AI-specific data formats (like tensors) on the fly, though the impact on compression ratios for non-standard datasets is still speculative. Early adopters will need to weigh these features against the learning curve of managing a system that blends hardware acceleration with adaptive software logic.
For now, VDURA positions this as a solution for organizations running large-scale AI pipelines where data movement is a critical bottleneck. Whether it delivers on its promises without introducing new operational complexities will determine its adoption rate in the field.









